
Contents
- 1 What is Multi-Talk?
- 2 Using Multi-Talk with WanVACE and FusionX
- 3 Step-by-Step: How to Use Multi-Talk in WanVACE
- 4 Animating Multiple Speakers and Conversations
- 5 Singing Duets and Passionate Performances
- 6 Advanced Control: Combining Reference Video & Audio
- 7 How to Install Multi-Talk on Your Computer
- 8 Final Thoughts
Imagine an AI that can make anyone say anything, perfectly lip-syncing to audio while controlling their movements and facial expressions — all for free and offline. This powerful tool, called Multi-Talk, combined with advanced models like WanVACE and FusionX, is revolutionizing AI-driven video animation. Whether you want to create talking heads, animated characters, or even multi-person conversations and singing duets, Multi-Talk has you covered. In this guide, we dive deep into what this technology can do, showcase exciting demos, and walk you through how to install and use it on your own computer, even if you have limited GPU VRAM.
What is Multi-Talk?
Multi-Talk is an audio-driven video animation model that goes beyond traditional single talking head generation. Instead, it allows multiple characters to talk and interact in the same video using different voices, all controlled by audio input. This means you can animate entire scenes with several people having conversations, each with their own realistic lip-sync, facial expressions, and body movements.
One of the most impressive aspects is how natural and fluid the animations look. The model doesn’t just move heads or lips; it animates the entire body and scene, capturing subtle nuances like blinking, looking away, and emotional expressions.

Versatility with Art Styles and Singing
Multi-Talk isn’t limited to realistic videos either. It can generate animations in various art styles, including 3D Pixar-like characters, anime, and even stylized illustrations. The lip-sync quality remains top-notch across all styles, handling complex and extreme expressions with ease.
Another standout feature is its ability to generate singing videos. Unlike many AI lip-sync tools that produce monotone, expressionless singing faces, Multi-Talk captures passion and emotion in singing performances. You can even create duets with multiple characters singing together, making it a fantastic tool for music videos or creative projects.
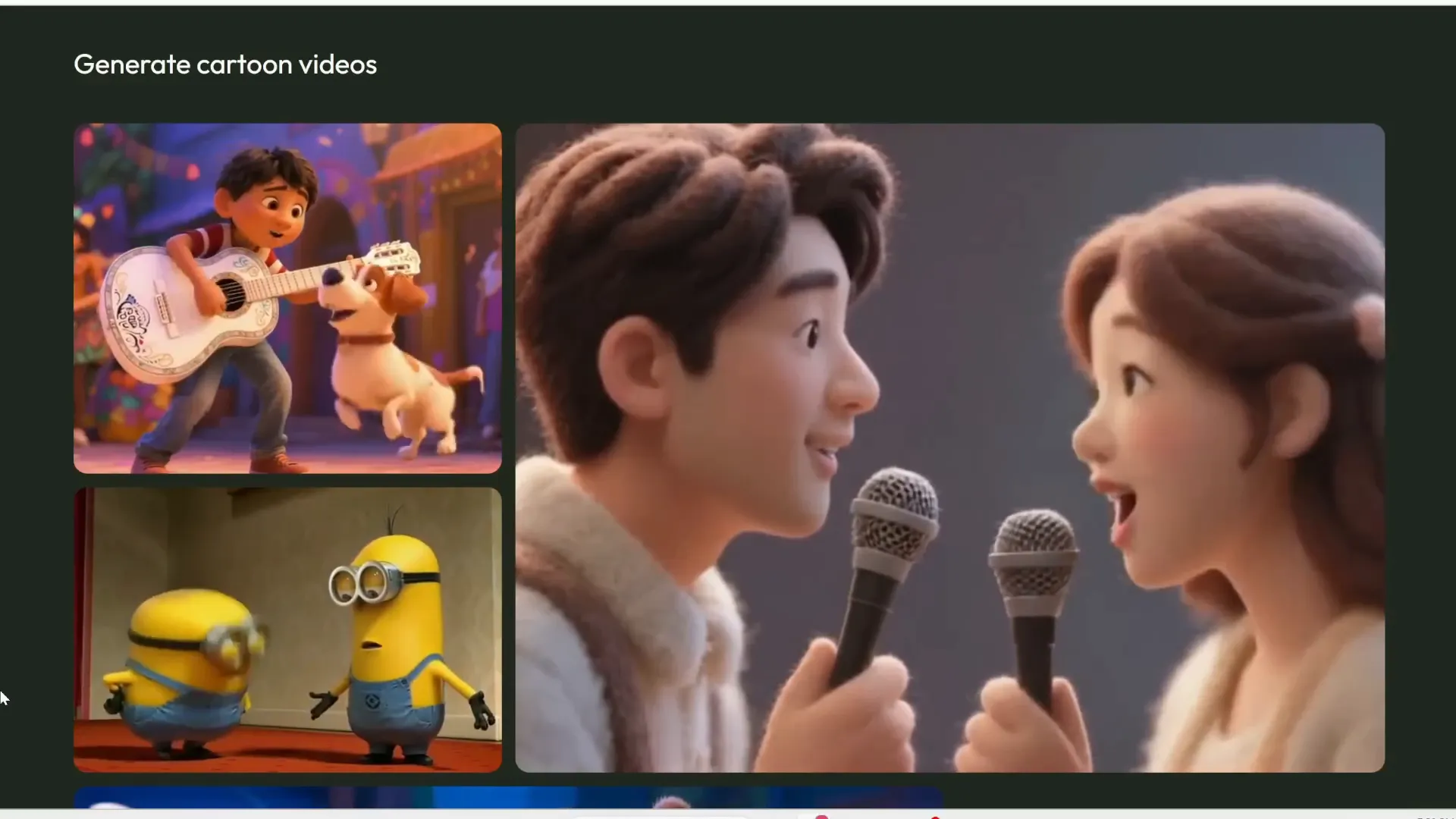
Text-to-Video Generation
Beyond image-to-video, Multi-Talk supports generating videos from text prompts. For example, you can describe a scene with a mischievous fox and a determined rabbit, complete with clothing details and props, and the AI will generate a video capturing all those elements naturally. This adds another layer of creative freedom, especially for artists and storytellers.

Using Multi-Talk with WanVACE and FusionX
To harness the full power of Multi-Talk, it’s combined with two other powerful tools: WanVACE and FusionX. This trio allows for ultimate control over video generation, including character movement, pose control, and fast, high-quality output.
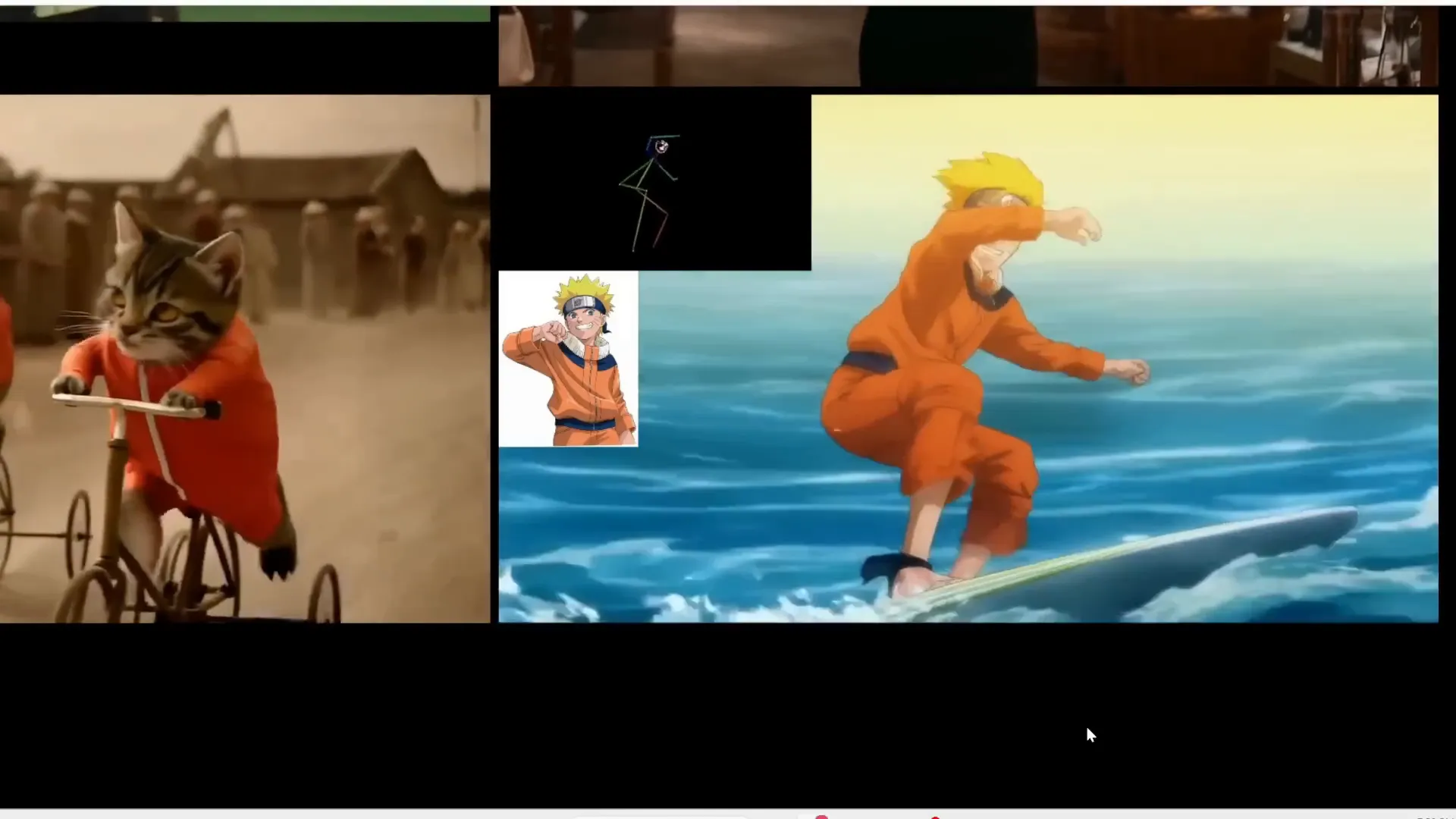
WanVACE: Flexible Pose Control
WanVACE is a beast of a tool that lets you apply the movements from a reference video onto your output video. Want Naruto to surf on a surfboard? Just provide a pose skeleton video, and WanVACE will transfer those motions onto your character. This flexibility means you can animate not just faces, but entire body movements, making your videos more dynamic and engaging.
FusionX: Faster and Higher Quality Generation
FusionX is a fine-tuned version of the 1 2.1 video generator, offering better video quality and much faster generation times. While 1 2.1 might need around 20 steps to generate a video, FusionX can do it in as few as six steps, cutting generation time by more than half. This speed boost is crucial for practical use, especially on machines with limited resources.

Step-by-Step: How to Use Multi-Talk in WanVACE
The easiest interface to use Multi-Talk currently is called Wan2GP. It even works on GPUs with as low as 6 GB of VRAM, making it accessible to many users.
Getting Started
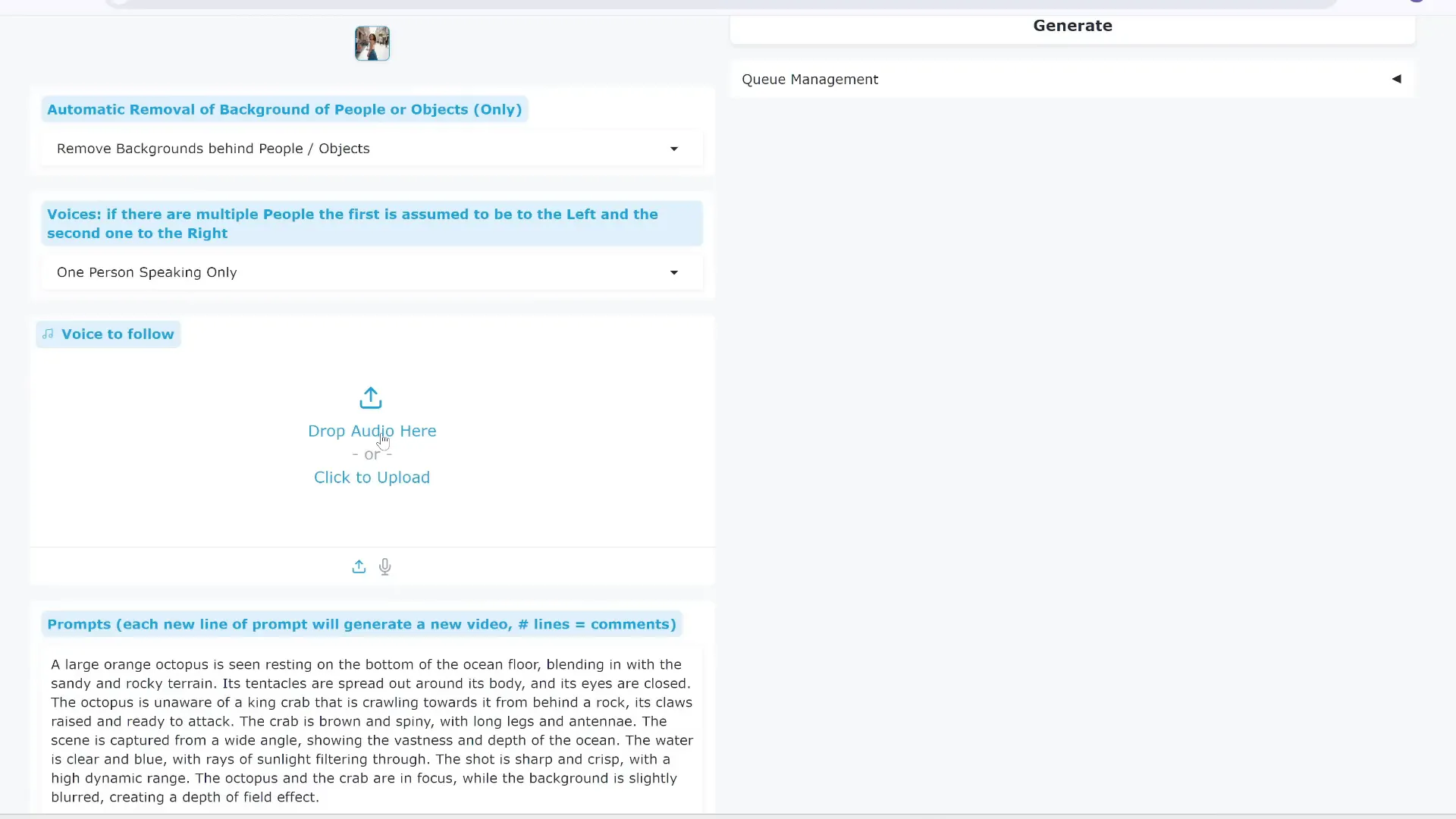
- Select the Multi-Talk model variant you want to use — options include 480p, 720p, or the Vase Multi-Talk Fusion X model, which is faster and more efficient.
- Upload a reference image of your character. You can also choose to remove the background and generate a new setting for the video.
- Upload an audio clip for the character to speak or sing.
- Enter a text prompt describing the scene or environment to add context.
- Set the video resolution, aspect ratio, and duration based on your audio length (typically 25 frames per second).
- Adjust inference steps, guidance, and audio lip-sync settings if desired, or leave them at default for simplicity.
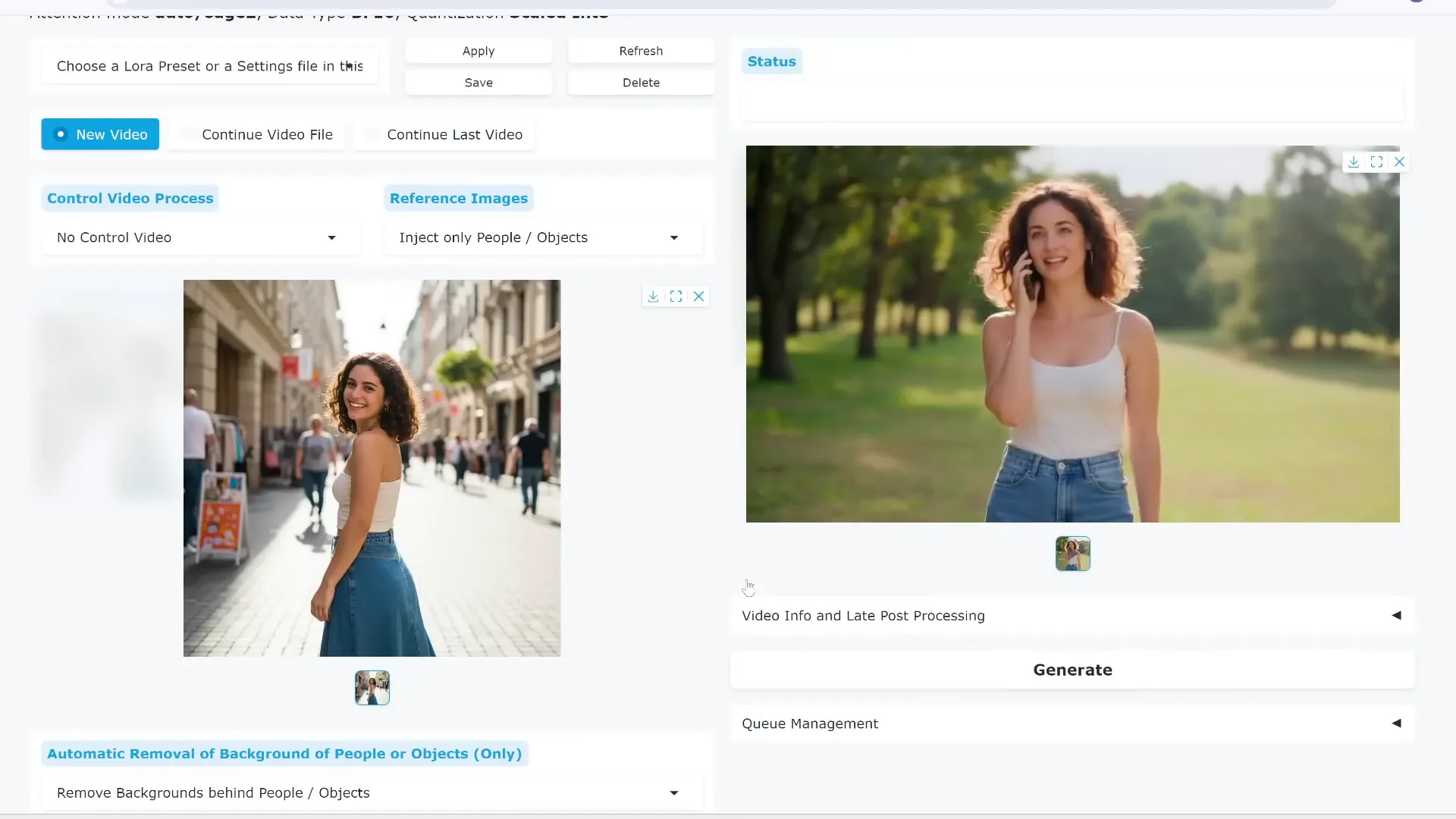
Generating Your First Video
After setting everything up, hit generate. The first time you run the process, the tool will download some large model files (up to 15 GB), but subsequent runs will be much faster. The output video will show your character realistically speaking or singing the uploaded audio, complete with natural head and body movements.
Handling Expressions and Emotions
Multi-Talk excels at capturing emotions by using reference images that already display the desired expression. For example, upload an image of an angry person and an angry audio clip, and the AI will generate a video that convincingly portrays anger, including voice pitch changes and facial emphasis.
Similarly, it can handle sadness, breathing, pauses, and crying, making it one of the most realistic lip-sync tools available.

Lip-Syncing Anime and 3D Characters
Anime fans will appreciate how well Multi-Talk lip-syncs Japanese audio to anime-style characters, even with tricky poses. It also works beautifully on 3D Pixar-style characters, maintaining high-quality lip-sync and natural movements.
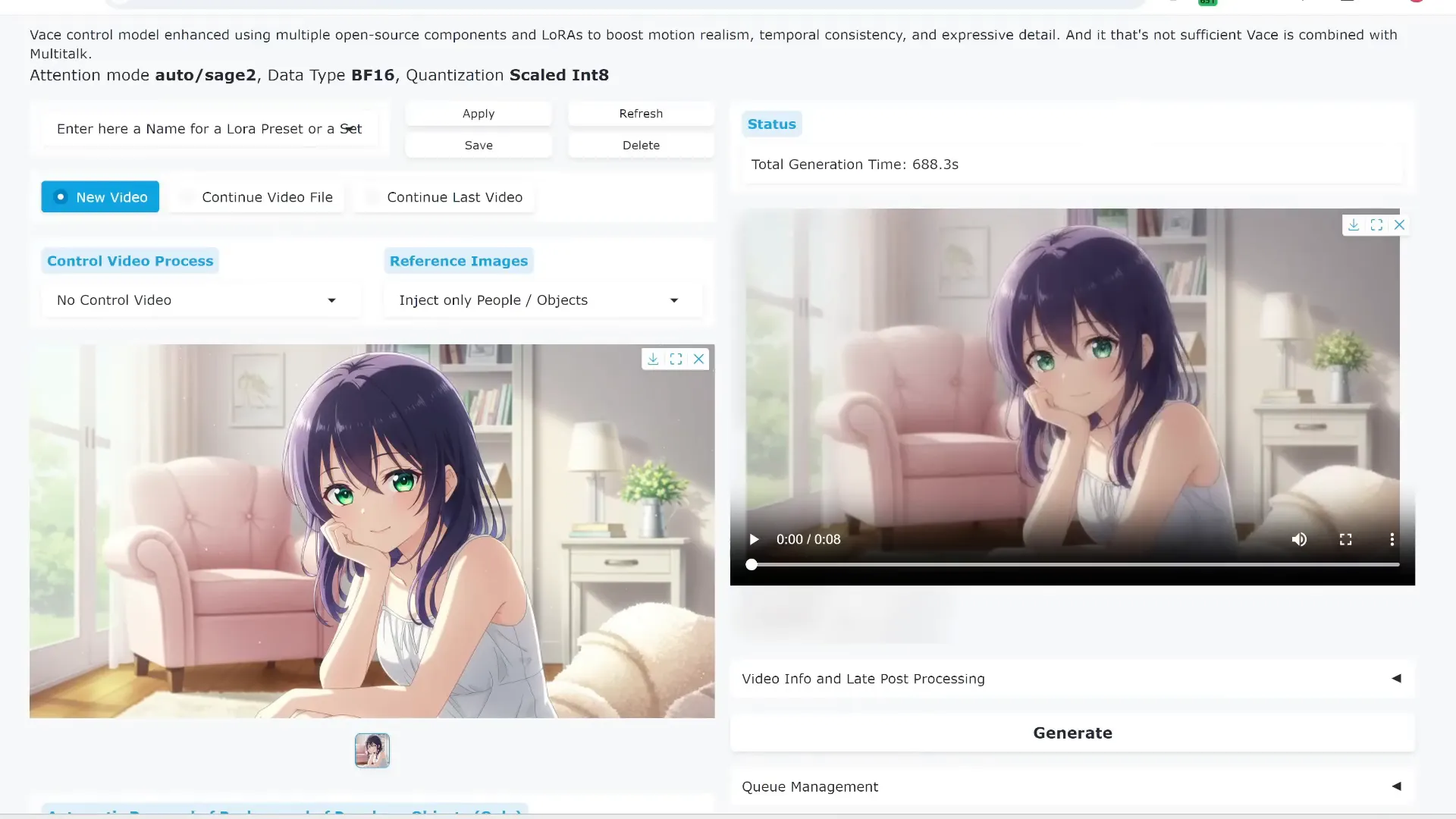
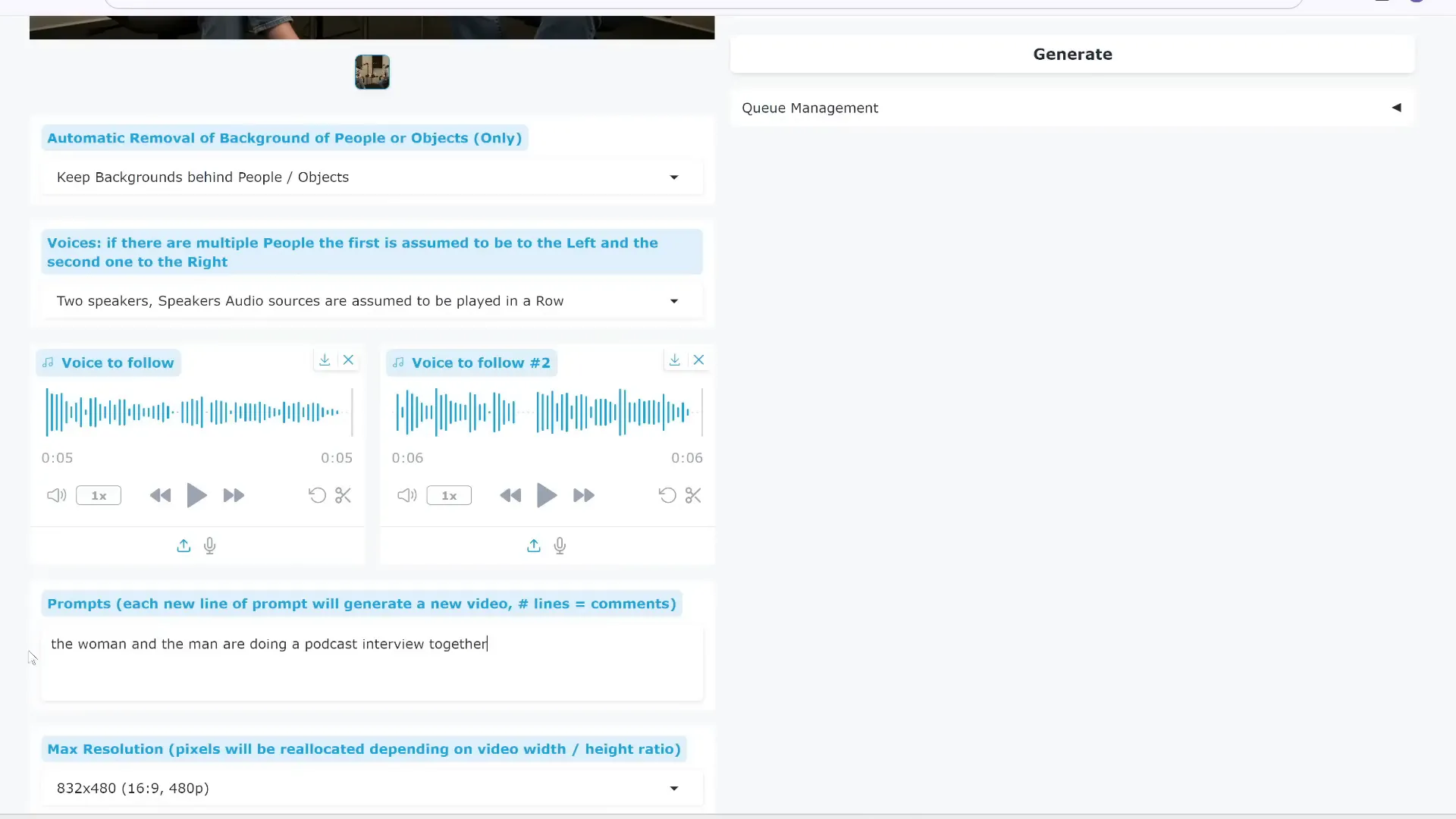
Animating Multiple Speakers and Conversations
Multi-Talk supports videos with multiple people talking or singing. There are three methods to handle multi-speaker audio:
- Automatic detection of which speaker says what (less reliable).
- Sequential playback of separate audio clips for each speaker.
- Parallel playback of audio clips for simultaneous speech (requires audio editing).
For best results, prepare your audio clips carefully and ensure your reference image matches the speaker positions (left/right). This flexibility lets you create realistic podcasts, interviews, or duets with synchronized lip-sync and natural gestures.
Singing Duets and Passionate Performances
Uploading two separate singing audio clips in sequence allows Multi-Talk to create realistic duet videos with expressive singing faces. This feature is outstanding compared to other AI lip-sync tools that often fail to capture singing emotion.

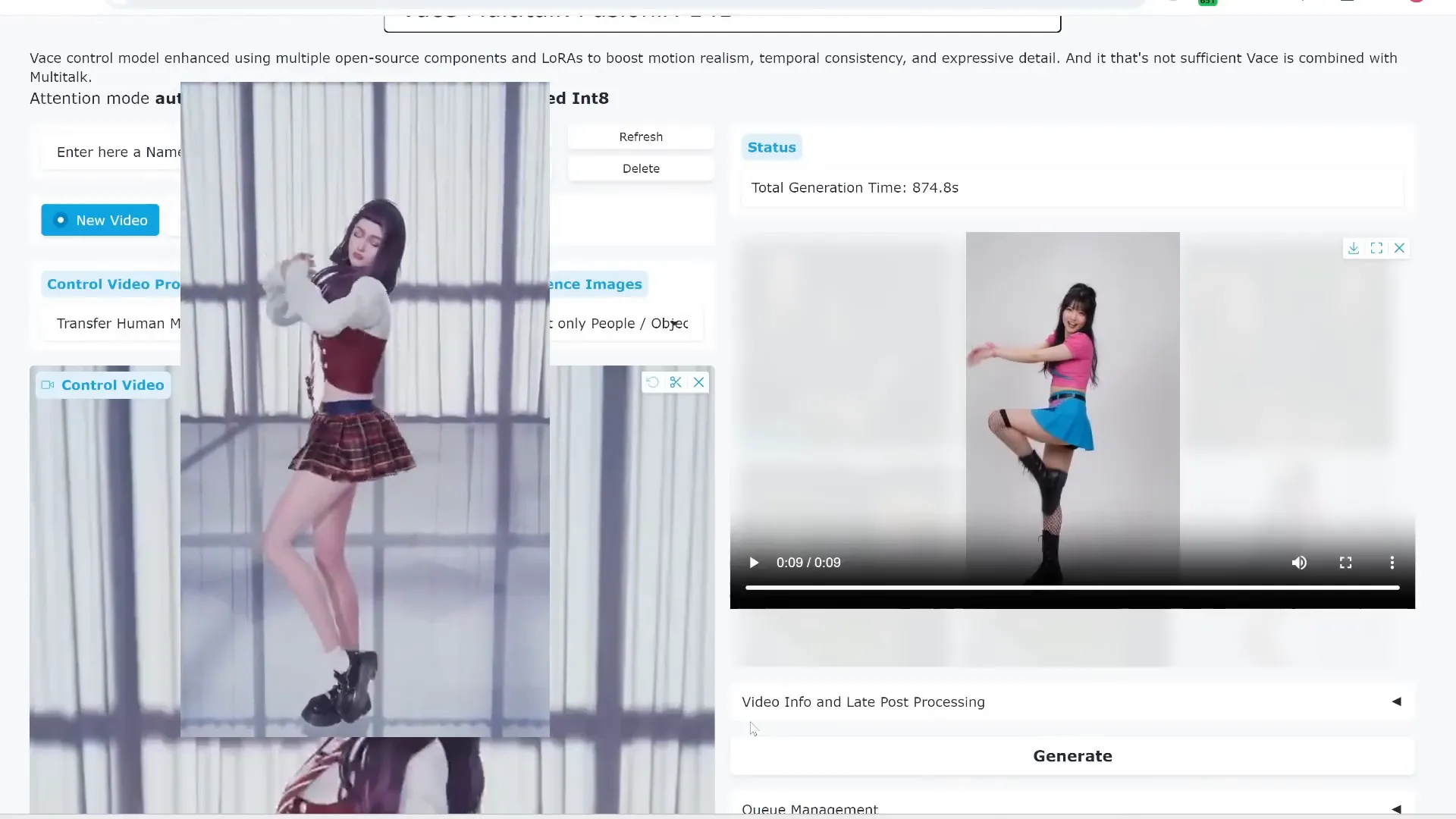
Advanced Control: Combining Reference Video & Audio
One of the most exciting features is the ability to upload a control video to transfer complex human motions, such as dancing, onto your character. Combined with an audio clip for lip-sync, this lets you create videos where your character moves naturally and speaks or sings simultaneously.
For example, you can have an imaginary K-pop idol dance according to a reference dance video while singing in Spanish, all generated by AI.
How to Install Multi-Talk on Your Computer
The recommended way to use Multi-Talk offline is through the Wan2GP interface, which supports low VRAM GPUs and offers a user-friendly experience.
To install:
- Clone or download the Wan2GP GitHub repository.
- If you already have Wan2GP installed, update it by running
git pullin the Wan2GP folder. - Activate your Python virtual environment (e.g.,
one2gp). - Install required packages using
pip install -r requirements.txt. - Run the Multi-Talk application using the provided command for image-to-video generation.
- Open the Gradio interface URL in your browser to start creating videos.
This setup works even with GPUs having as little as 6 GB VRAM, making it accessible to many users.
Final Thoughts
Multi-Talk combined with WanVACE and FusionX is a groundbreaking AI toolset for anyone interested in creating realistic, expressive, and highly customizable talking videos. From single speakers to multi-person conversations, from realistic faces to stylized anime and 3D characters, and from simple speech to passionate singing — the possibilities are vast.
Best of all, this entire pipeline is free and can run offline, giving creators unmatched control and privacy. Whether you’re an animator, content creator, or just exploring AI, Multi-Talk is a must-try tool that pushes the boundaries of AI video generation.
Ready to dive in? Follow the installation steps, experiment with your own images and audio, and unlock a new world of AI-driven video creation.






